
学习目标
完成本单元后,您将能够:
- 确定您的示例集和事后偏见。
- 建立预测。
理解示例集
现在您已经创建了几个自定义公式字段并完成了细分,您几乎已准备好选择数据集中的哪些记录作为示例。当您第一次构建预测时,爱因斯坦会从您提供的数据中“学习”。它需要深入了解您的数据并从中构建预测模型,确定哪些字段可能会影响预测结果。
这可以让您考虑发票数据集中的所有字段。作为示例包含的正确数量的字段是多少?对于爱因斯坦预测构建器,更多数据通常更好。事实上,我们建议首次使用所有或几乎所有选定的字段构建预测。爱因斯坦预测构建器查找具有最强预测能力的字段,因此如果您在没有充分理由的情况下删除字段,则可能会意外引入偏差。
回顾一下,爱因斯坦预测构建器使用数据集中的信息进行预测。如果预测器很有可能影响预测结果,则预测器显示更高的影响值。对于Lightning Energy,客户名和姓名字段可能是弱预测指标,因为它们似乎与客户是否可能延迟付款无关。但是为了以防万一你还是包括它们。
识别后见之明的偏见
你需要注意的一个变量是事后偏见。也称为数据泄漏,当您在未来的示例集中包含数据时会发生事后偏见 – 它仅出现在您要预测的事件之后。
对于Lightning Energy来说,事后偏见的一个例子是Late Fee字段。Lightning Energy仅在客户错过付款截止日期后才收取滞纳金。如果使用此字段构建预测,则会将有关未来的信息“泄漏”到模型中。当你这样做时,爱因斯坦将该字段标记为延迟付款的强预测因子,但实际上,延迟费用字段不是预测变量。因此,您继续使用您在上一个单元中学习的分段步骤从数据集中排除延迟费用字段。
爱因斯坦在捕捉无益变量方面做得非常好,但可能会错过一些。这就是为什么总是仔细检查你的领域并扫描任何可能引入事后偏见的原因是个好主意。
建立预测
现在是时候把它们放在一起了。让我们建立一个预测。请记住,爱因斯坦支持对同一个对象进行多次预测,但如果你试图快速连续建立它们,爱因斯坦只会建立在第一个上。我们建议每天在同一个对象上创建一个预测。
- 从“设置”中,输入Einstein Prediction Builder“快速查找”框并选择“ 爱因斯坦预测生成器”。或者,单击入门的爱因斯坦预测生成器瓦。
- 如果这是您第一次使用爱因斯坦预测构建器,则还需要在启动页面上单击 “开始 ”。
- 单击新预测。
- 命名您的预测Late Payments Prediction。API名称字段根据您的标签自动填充。单击下一步。

- 选择“ 发票”对象,然后选择“ 是”,将焦点放在一个段(高级)上。选择“ 自动转帐”字段,“ 等于”运算符,然后选择“ 假”值。在这里,您要选择在模型中使用哪些数据。单击下一步。
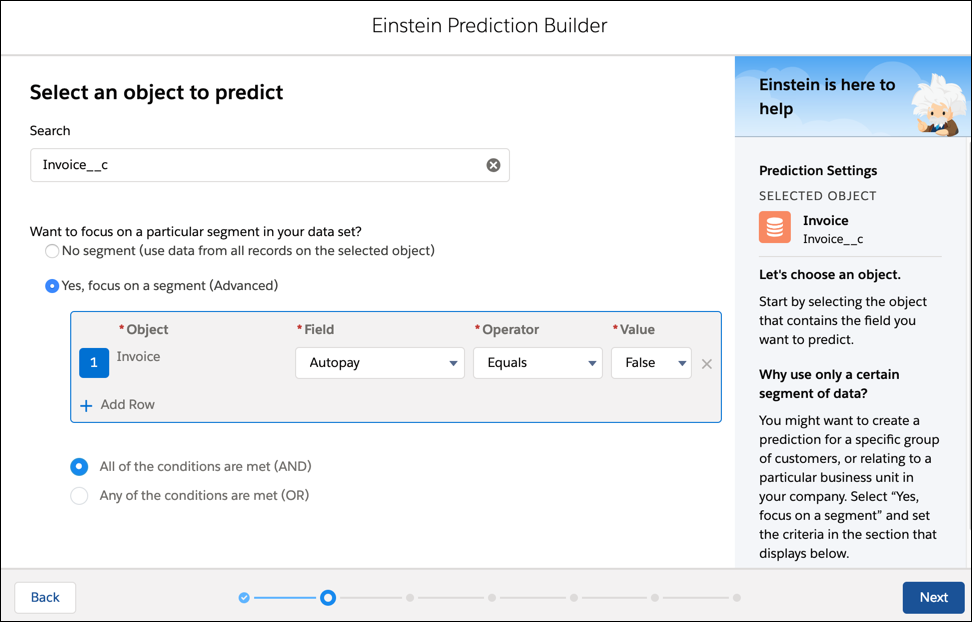
- 搜索并选择您之前创建的延迟付款公式字段。这是您要预测的字段。
- 爱因斯坦需要知道使用哪些记录作为例子。您想使用过去的发票,以便知道它们是否是延迟付款。在这种情况下,过去的发票是不再处于“待处理”状态的发票。因此,选择“ 发票状态”字段,“不等于”运算符和“ 待定” 值。单击下一步。
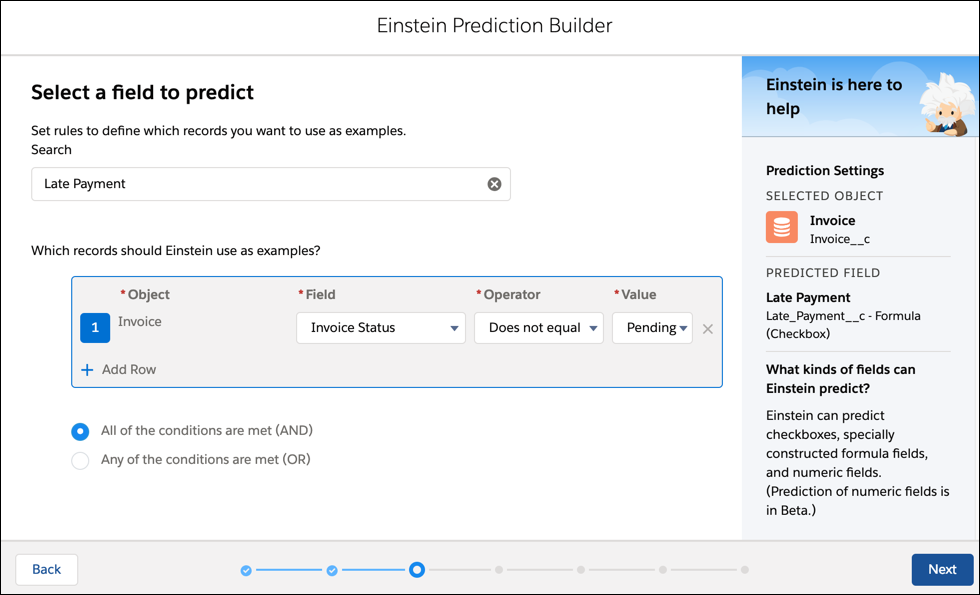
- 一个常见的错误是只选择那些值为“True”的记录 – 在这种情况下,这只是“延迟付款”公式为True的Invoice对象的行。然而,爱因斯坦从正面和负面的例子中学习,所以你必须确保给它两个例子!这就是为什么我们选择所有过去的发票而不仅仅是那些迟付的发票。
- 查看爱因斯坦的字段以进行分析以进行预测。在这种情况下,由于上面讨论的事后偏见,取消选中延迟费用字段。单击 下一步。

- 将爱因斯坦保存预测的字段命名为。输入Predicted Late Payments字段标签。按Tab键填充字段名称,然后单击“ 下一步”。

- 检查您的选择。要进行更改,请使用“ 后退”按钮。对选择感到满意后,单击“ 构建预测”。在下一页上,单击“完成”。
爱因斯坦需要几个小时来分析数据并开始做出预测。在下一个单元中,我们将查看结果并向您展示如何将预测付诸实践。