
学习目标
完成本单元后,您将能够:
- 导航到故事的“差异是什么”见解并探索它们。
- 理解变量之间的关系。
- 使用这些见解来帮助最大化客户终身价值(CLV)。
了解什么是差异见解
注意
本单元中的说明假设您已根据“使用故事获取大图片”中的步骤成功创建了爱因斯坦探索故事,这是此Trailhead模块中的第一个单元。
在爱因斯坦发现中,什么是差异洞察力是比较见解,可以帮助您更好地理解解释变量与故事中目标(目标结果变量)之间的关系。这些见解基于对数据集的统计分析,可帮助您确定哪些因素会导致结果变量的最大变化。爱因斯坦发现使用瀑布图来帮助您在“什么是差异”洞察中可视化比较。
通过隔离解释变量,您可以看到并了解它与整体的关系,以及它与另一个解释变量的比较。例如,您可以将制造客户的销售业绩与整体销售业绩进行比较。此外,您还可以比较制造和分销客户之间的销售业绩。最后,您可以添加过滤器以关注较小的数据片段(例如特定的销售区域)。
找到使用CLV的最佳客户
在本单元中,我们使用What Is The Difference的见解来探索您之前创建的故事(请参阅“爱因斯坦发现经典”模块中的“创建故事”)。回想一下,这个故事的目标是最大化客户终身价值(CLV)。CLV是一种度量标准,用于预测公司与客户关系的整个生命周期内的盈利能力。
选择什么是差异洞察类型
在Insight导航栏上,单击右上角的向下箭头,然后单击“区别是什么”。

“数据洞察”导航栏显示此类别但不显示图表。要查看图形,必须先选择一个变量。
将解释变量与全球平均值进行比较
在我们的示例故事中,全局平均值表示数据集中所有数据的CLV。将单个变量的CLV与全局CLV平均值进行比较是有用的。要选择变量,请在“数据洞察”导航栏左侧的“ 关联到(选择变量) ”中选择“ 行业 – 运输”。
计算完成后,您会在瀑布图中看到最具统计意义的洞察力。
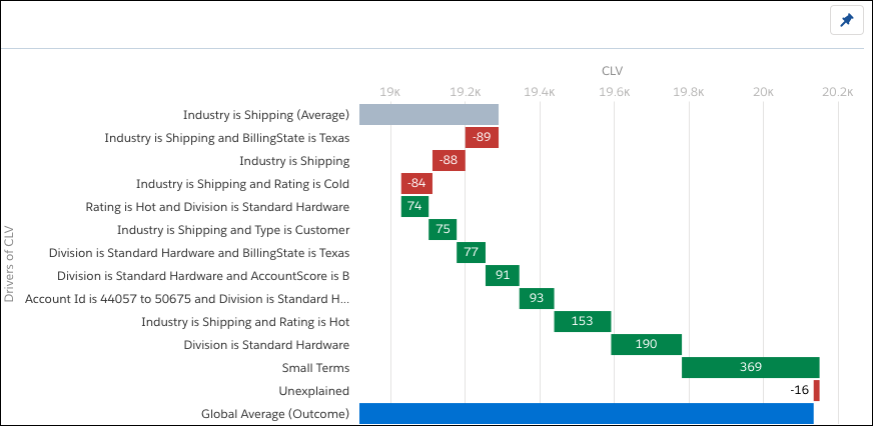
CLV出现在图表的顶部,提醒我们将此故事配置为最大化CLV作为结果变量。
注意
如果这里的图像与您在爱因斯坦发现中看到的屏幕略有不同,请不要担心。界面元素通常是相同的,但一些细节 – 包括它们显示的数据 – 可能略有不同。
在图表的顶部,标记为Industry is Shipping(Average)的灰色条显示行业运输时的平均CLV。要查看更多详细信息,请将鼠标悬停在灰色栏上。
当我们的故事将CLV最大化为结果变量时,图表中的红色条表示将CLV从平均值降低的条件。将鼠标悬停在图表中的红色条上。

在此示例中,当Industry is Shipping并且BillingState是Texas时,CLV是-89,或低于平均值89。请注意,左侧相应的洞察描述以灰色突出显示。
当我们的故事将CLV最大化为结果变量时,图表中的绿色条显示了CLV从平均值增加的条件。将鼠标悬停在图表中的绿色条上。

在此示例中,当Division是标准硬件时,CLV高于平均值190。请注意,左侧相应的洞察描述以灰色突出显示。

注意
如果我们的故事目标是最小化CLV,那么绿色和红色的颜色将会颠倒过来。
图表底部的蓝色条显示全局平均值(结果),表示数据集中所有数据的平均CLV(20,136)。

比较两个变量
接下来,我们添加第二个解释变量并比较两者。在Insights导航栏上,转到右侧的Between(选择变量),然后选择Industry – Technology。
计算完成后,您会看到比较两个行业的瀑布图。
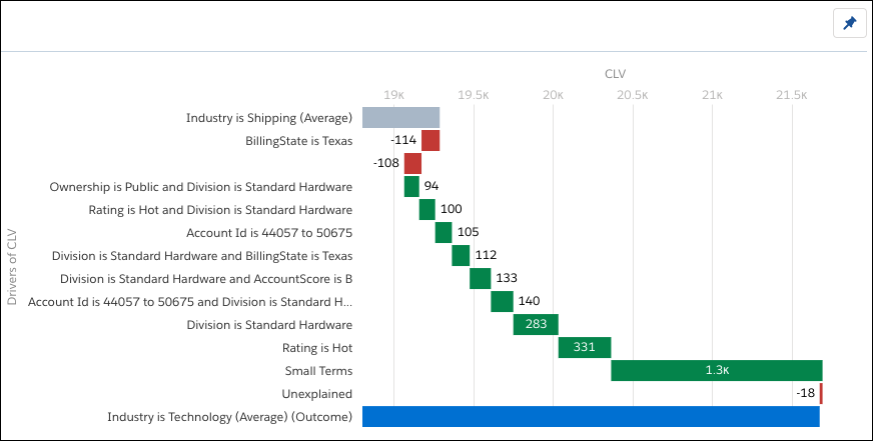
一目了然,这张图表显示,CLV for Industry is Technology (平均值)在很多方面优于Industry is Shipping(平均值)。例如,当账户被评为热门时,科技的终身CLV比运输更好。但在德克萨斯州,海运拥有比科技更好的CLV。
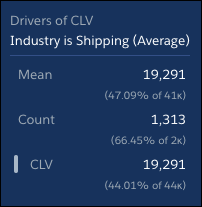
将鼠标悬停在图表顶部的灰色栏上,显示Industry is Shipping(Average)。
将鼠标悬停在图表底部的蓝色条上,显示行业是技术(平均值)。
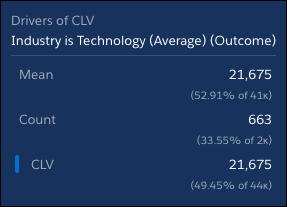
比较实际的CLV数字证实了技术的平均CLV高于Shipping。
添加过滤器
(可选)您可以添加过滤器以进一步将分析重点放在数据的子集上。在“数据洞察”导航栏的最右侧,单击“ 搜索故事洞察”,然后选择“ 类型 – 咨询”。

计算完成后,您会看到一个瀑布图,比较两个行业只有咨询数据。
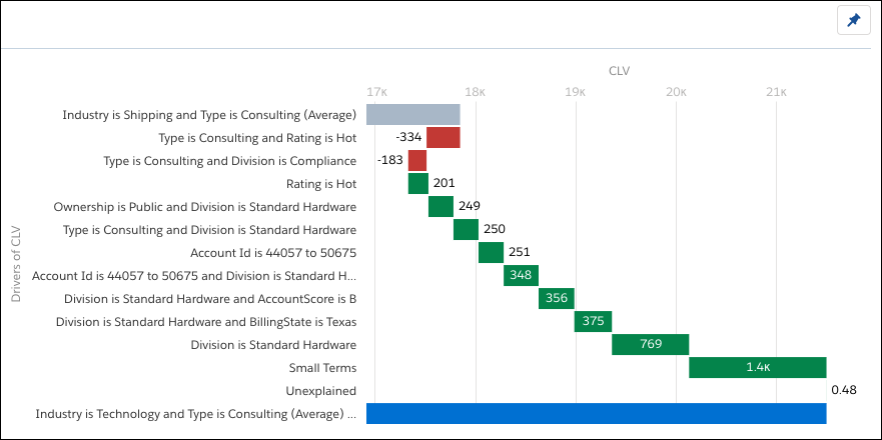
在此示例中,小型术语和部门是标准硬件,显示了在Type是咨询时最大化CLV的最高相关性。
结论
在本单元中,您继续担任主要汽车供应商的运营副总裁。您深入研究了您在爱因斯坦发现数据集成模块中创建的故事。您学会了如何解释爱因斯坦发现在您的数据中发现的几个见解。您查看详细说明所发生情况的描述性见解,并查看比较见解,以显示比较变量时的差异。这个故事充满了关于您的数据的见解。探索故事有助于您发现帐户的CLV与可能影响CLV的其他变量之间的关系。












