学习目标
完成本单元后,您将能够:
- 导航到一个故事,为什么它发生了见解并探索它们。
- 了解因素的组合如何影响结果。
- 了解不相关的因素如何影响结果。
了解为什么会发生这种见解

注意
本单元中的说明假定您已根据“创建故事”中的步骤成功创建了爱因斯坦探索故事,这是此Trailhead模块中的第一个单元。为什么它发生的见解有助于您深入了解导致结果的确切因素。
注意
它为何发生的原因是指高度相关 – 不一定是因果关系。使用为什么会发生这些见解,深入了解导致故事目标的各种因素。这些见解基于对数据集的统计分析。爱因斯坦发现使用瀑布图来帮助您想象为什么会发生这种见解。
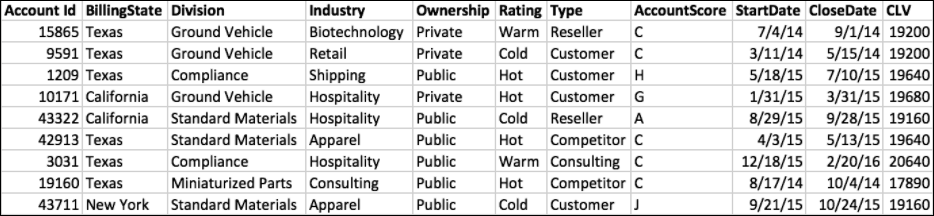
你的故事的结果变量和目标
配置故事时,您告诉Einstein Discovery在AcquiredAccount中最大化CLV变量。CLV是您故事中的结果变量,最大化CLV是您的目标。本故事中的所有见解都向您展示了变量和变量组合如何帮助解释CLV的变化。列表中的最高见解反映了结果变量中统计上最显着的变化。
选择“为什么会出现洞察力类型”
在Insight导航栏上,单击“ 为什么会发生这种情况”。

在搜索故事洞察中,单击向下箭头并选择分区 – 海军。
爱因斯坦发现刷新了洞察清单。

注意
如果这里的图像与您在爱因斯坦发现中看到的屏幕略有不同,请不要担心。界面元素通常是相同的,但一些细节 – 包括它们显示的数据 – 可能略有不同。我们正在查看CLV值的瀑布图,这可以帮助解释为什么属于海军部门的客户与普通客户不同。
- 全球结果代表所有部门(包括海军)的CLV平均值。
- 分部是海军(结果)代表海军师的CLV的平均值。
哇,我们公司的海军部门拥有比平均值更高的CLV!海军客户本质上更好吗?也许它们与其他客户基本相同,但存在增加CLV的潜在相关性。也许它只是两者兼而有之。我们来看看。
将鼠标悬停在Global Outcome栏上以获取更多信息。

全球成果的平均值为20,136,计数为10,000。这些数据告诉我们什么?所有部门(包括海军)的平均CLV为20,136美元,并且有10,000条记录。
将鼠标悬停在海军(Outcome)栏上以查看更多信息。

Division is Naval(结果)的平均值为20,488,计数为 328。这些数据告诉我们什么?海军部门的平均CLV为20,488美元,有328个客户。对于所有客户,海军客户的平均CLV比CLV高出352美元!现在让我们找出原因。
了解该部门是海军洞察力
将鼠标悬停在该部门的海军栏上可查看更多信息。
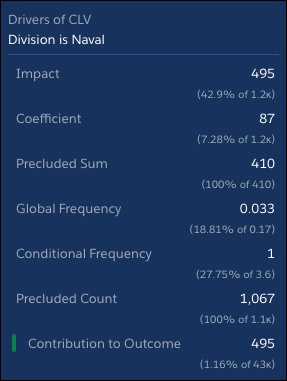
我们可以从这些信息中了解很多关于海军客户的信息。让我们按以下顺序查看数字,以便我们可以先了解构建块。
- 全球频率为3.3%。我们海军部门的客户总数仅占客户总数的3.3%。多么不幸,因为我们的海军客户的CLV高于平均水平。也许是时候尝试收购潜在的海军客户了?或许我们意识到海军市场很小,我们专注于其他部门?
- 条件频率为1(100%)。在我们的案例中,类别部门中100%的记录是海军在海军部门。也许这些信息显而易见。
- 系数是87。这告诉我们什么?如果没有其他因素,那么海军部门的CLV将比平均值高出87美元。这个数字告诉你,除法是海军的简单事实会影响海军师的CLV。小费这是您使用此号码的一种方式。如果这个数字很高,比如1000,那么作为海军客户的影响,没有考虑其他因素,是CLV比平均值高1000美元。呜啊!但是你看到观察到的结果远远低于1000美元。这些信息表明海军客户有可能具有价值,但其他东西正在拖累这个数字。
- 排除的总和是410。对普通客户的影响包括海军部门客户的影响以及非海运部门客户的影响。爱因斯坦发现计算的影响,客户谁是不是在海军部门对谁的客户的CLV 是在海军部门。在我们的例子中,删除非海军部门的所有影响的影响是将CLV增加410.00美元。
- 影响是495。此数字总结了之前的所有其他数字。影响考虑了仅仅是海军客户的影响以及作为海军的整体客户的百分比。影响还增加了其他非海军客户的影响力。在我们的例子中,它告诉我们,如果不是相关和非相关类别中的其他因素,海军客户的CLV将比平均值高495美元。这是一个重要的数字!为什么我们没有意识到这种潜力?在接下来的部分中,我们会发现。
我们完成了该部门的一级分析是海军类别。现在看下一个类别,与Division相关的是Naval。
分裂是海军时了解变量
此类别告诉您变量的不同组合如何协同工作以影响CLV。

小费
相关部分是爱因斯坦发现的最佳部分之一。您可以真正了解您甚至没有考虑的重要但非显而易见的因素!
将鼠标悬停在评级上是热门,而部门则是海军以显示详细信息。

这个数据令人惊讶。海军客户应该拥有高CLV。具有热评级的客户应该是有利可图的。但海军部门的热门评级客户的CLV低于预期。以下是观察结果:全球53%的时间评级为热点,但当知道该部门是海军时,它会变为92.4%。由于这些情况,CLV减少了172.1。
谁知道?被评为热门的海军客户拖累海军客户的整体CLV。为什么?也许我们的评级系统有问题。Naval客户可能对我们使用Hot帐户采取的方法反应不佳。
还有更多的惊喜。92.4%的海军客户被评为热门,这是拖累CLV的客户比例非常高。绝对值得深入研究这个!请注意自己稍后与您的团队进行调查。
让我们进一步研究重要但非显而易见的因素。将鼠标悬停在类型为客户和事业部是海军:

此栏显示-294的影响,这意味着直接客户(而不是合作伙伴或经销商或某些其他类型的渠道)的海军客户确实拖累了CLV。和62%,我们的海军客户都是直接客户。哇。这一见解让您意识到爱因斯坦发现的强大之处。在我们最有价值的部门中,超过一半的客户似乎严重低于平均CLV。是时候调查海军部门客户渠道的情况了!
最后,将鼠标悬停在与分部相关的小条款上是海军:

此类别将CLV降低254美元。
了解不相关的类别
我们从与海军师有关的类别中获得了一些有用的信息。现在让我们来看看无关类别。但为什么我们要查看不相关的信息?好问题。本节中的信息是“不相关的”,这意味着它不是特定于海军部门的客户。本节向我们展示了对所有客户产生正面或负面影响的因素。本节还说明了海军客户相对于一般客户的影响频率。让我们更具体一点。
- 如果一个很好的事情发生比较频繁的客户海军比它为所有客户,效果是积极的。
- 如果海军客户的好事发生的次数少于对所有客户的好处,那么效果就是负面的。
- 如果不好的事情发生比较频繁的客户海军比它为所有客户,效果是负面。
- 如果海军客户发生的不好事情比对所有客户发生的情况要小,那么效果是积极的。
换句话说,爱因斯坦发现很复杂,足以说明事情发生的不良事件往往会产生积极的影响。要查看更多示例,请查看我们的图表。
将鼠标悬停在无关小贡献者栏上以显示详细信息。

您可以看到所有其他因素(总计3,803个小贡献者)共同占CLV 额外的465美元。
你很快意识到了无关部分的力量。它为您提供有关事情发生原因的更深入信息。换句话说,它为您提供了更多权力来信任(或给予建设性反馈)合适的人。
我们已经看完了无关因素。现在让我们转到Unexplained部分。
理解不明原因的部分
看着原因不明的现象听起来很神秘。真的,这只是两者之间的区别:
- 爱因斯坦发现如果知道所有因素就会做出的预测
- 观察到的数据集中实际发生的结果
有时此类别中没有条形,这意味着模型正在进行准确的预测。如果原因不明的条形图很小,则意味着爱因斯坦发现正在构建一个可预测的模型,用于识别解释观察结果的因素。使用相同模型绘制的其他见解产生的结果与之前的见解一致。
将鼠标悬停在原因不明的栏上以显示详细信息。

在这种情况下,实际CLV(根据数据集计算)和预测的CLV(来自爱因斯坦发现的数据模型)之间的差异为54美元。