
学习目标
- 确定Apex元数据API的用例。
- 列出Apex Metadata API的主要功能和局限性。
Apex Metadata API入门
假设您是Salesforce开发人员或ISV,并且为您的应用程序创建了一个很酷的新自定义功能,其中包含一些元数据更改。要将此功能部署到支持的组织中,请为管理员编写一组说明,以便他们可以进行更新。这些指令将引导他们完成Salesforce Setup UI中各个位置的更改。这听起来太熟悉了吗?除非你真的喜欢技术写作(就像我们在Salesforce做的那样),如果有一个更简单的方法来做你的更新不是很好吗?
好消息是,您可以使用Apex Metadata API来改进此过程。 API允许您直接从Apex进行元数据更改。因此,您可以使用Apex的所有便利功能来构建自定义设置UI,以在幕后更新元数据。您也可以通过这种方式自动进行配置更改。让我们来深入看一些使用Apex元数据API的例子。
这个API能为我做什么?
假设您支持多个组织,并且您已经创建了自定义字段。你想把你的新字段添加到所有组织的页面布局中。这种类型的配置信息存储在组织中的元数据类型和组件中。
您可以创建一个使用Apex元数据API的脚本,将您的新字段直接从Apex添加到您所有组织中的页面布局。组织中的元数据在幕后更新,以便您的管理员不必在每个组织中进行手动更改。
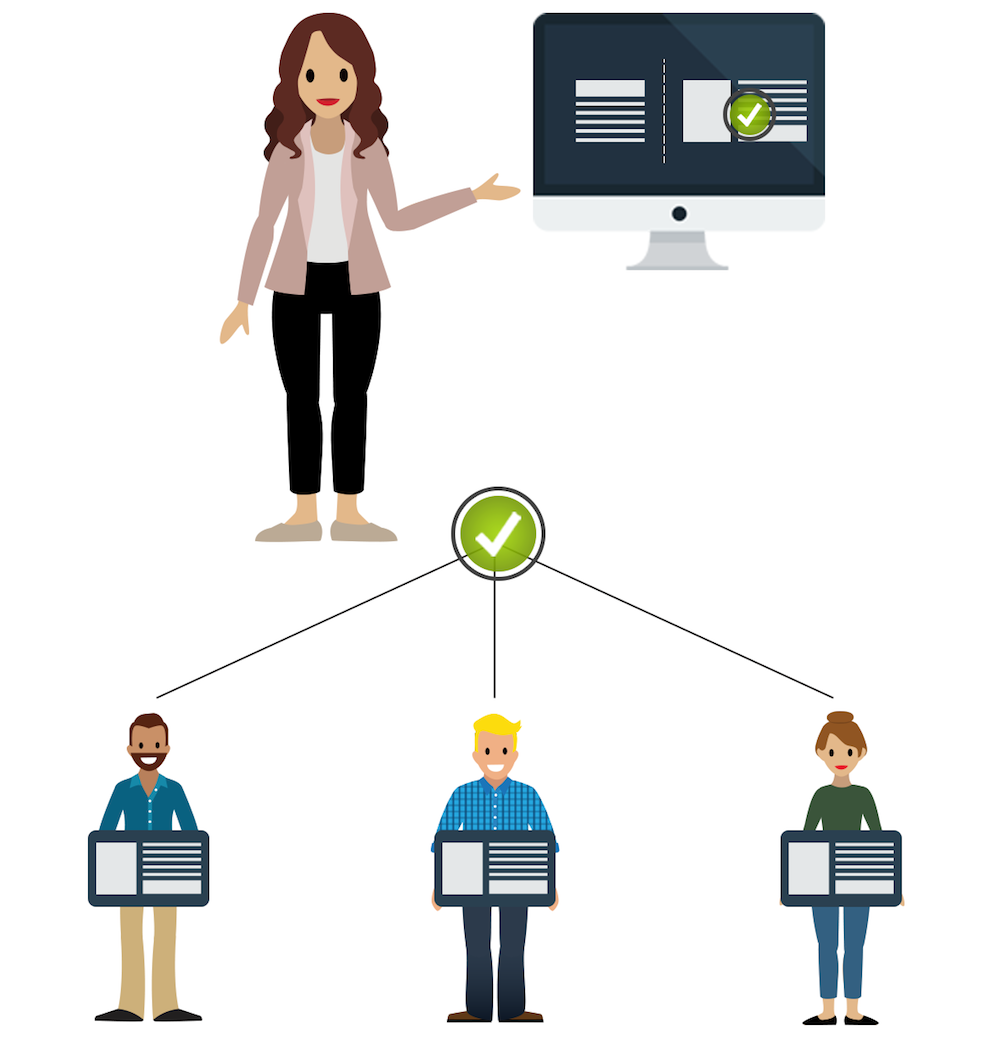
Apex元数据API还使您能够为您的功能建立自定义安装体验。例如,假设您已经创建了自定义元数据类型来支持新功能。您的自定义元数据类型的记录必须针对不同的国家进行不同的配置。您可以使用Apex Metadata API构建一个设置向导,通过一系列步骤来指导管理员配置记录。这种自动化功能可以让您的管理员不必在设置界面中进行手动更改。
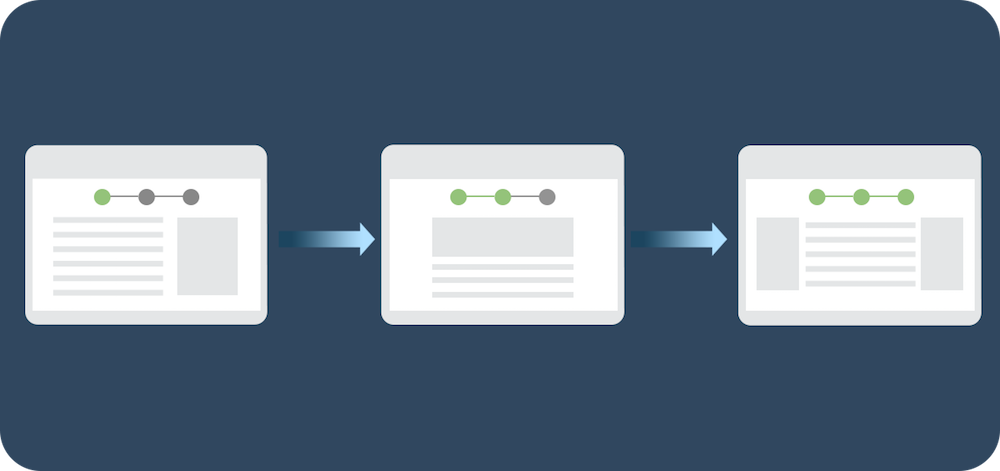
直接从Apex处理元数据
要使用Apex代码中的元数据,请使用Metadata命名空间中的类。您可以访问两种顶级元数据类型:页面布局和自定义元数据类型的记录,这使您能够处理组织的大部分自定义和配置。
那么,您可以使用Apex元数据API来做些什么?您可以从组织中同步检索元数据。然后,您可以检查此元数据并进行更新,也可以创建元数据。使用异步部署将更新后的元数据部署到组织中非常简单。要在部署完成时得到通知,可以实现回调。
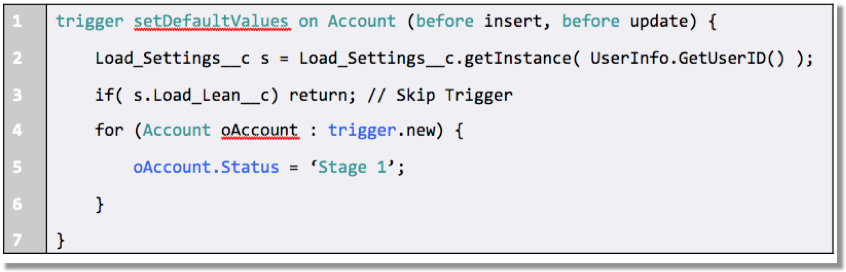
让我们先看一下Apex代码,看看Apex元数据API可以做什么。以下片段使用Metadata.CustomMetadata类创建自定义元数据类型的记录。我们可以直接从Apex将这个新记录部署到一个组织中,就像我们在本章后面看到的那样。
Metadata.CustomMetadata customMetadata = new Metadata.CustomMetadata();
customMetadata.fullName = 'MyNamespace__MetadataTypeName.MetadataRecordName';
Metadata.CustomMetadataValue customField = new Metadata.CustomMetadataValue();
customField.field = 'customField__c';
customField.value = 'New value';
customMetadata.values.add(customField);
- 在当前版本中,我们只支持两种元数据类型:页面布局和自定义元数据类型的记录。
- 支持读取,创建和更新元数据,但不支持删除元数据。
- 我们没有可让您跟踪部署状态的API。但是,您可以设置在部署完成时调用的回调。
安全性如何?
元数据是强大的东西。所以也许你担心安全问题。别担心!信任是Salesforce的头号价值,Apex Metadata API的构建是一个值得信赖的界面。安装的软件包必须通过Apex认证,或者订户组织必须启用设置才能部署Apex元数据。您可以跟踪安装程序审计跟踪中启动部署的名称空间。
在您有机会了解Apex元数据API可以做什么之后,我们会在即将到来的单元中更详细地讨论安全性。
对ISV的一个注意
虽然本模块中的示例以企业为重点,但如果您是ISV的开发人员,Apex元数据API也可能很有用。创建特定于您的应用的设置UI并自动进行配置更改可以提高您的业务。使用Apex元数据API,您可以:
- 为非专业人士提供更快更轻松的设置体验,为您和您的客户节省资金。
- 完全通过自动化完成一些设置步骤。
- 通过向管理员提供他们可以使用的工具而无需专业服务专业知识,为管理员提供动态更改配置的功能。
- 通过降低客户尝试您的应用程序的障碍来提高产品的采用率。
- 保护你的知识产权。 在应用程序中更新受保护元数据的能力意味着您可以隐藏更多来自客户的配置。
- 消除对远程站点设置的依赖,降低代码的复杂性并简化客户的设置。
 如果您创建了现场服务配置文件,请在这些配置文件上执行以下步骤而不是标准配置文件。
如果您创建了现场服务配置文件,请在这些配置文件上执行以下步骤而不是标准配置文件。