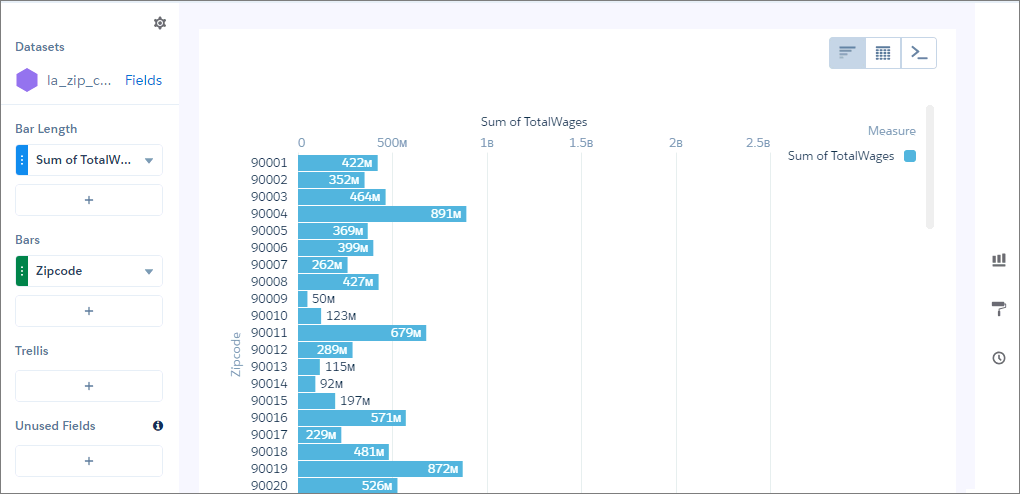
Country,Country_code,Region,Accounts,Value
Australia,aus,South Pacific,1898,22930651
China,chn,East Asia,2051,29754009
Europe,eur,Europe,4668,61238042
France,fra,Europe,2303,28746829
India,ind,Asia,2721,32037499
Italy,ita,Europe,1722,26340986
Japan,jpn,East Asia,2872,36916012
Russian Federation,rus,East Europe,1847,27387456
South Africa,zaf,Africa,879,9794857
South Korea,kor,East Asia,1643,21934785
United States of America,usa,North America,6527,87044191
Country,Country_code,Region,Accounts,Value
Australia,aus,South Pacific,1898,22930651
China,chn,East Asia,2051,29754009
Europe,eur,Europe,4668,61238042
France,fra,Europe,2303,28746829
India,ind,Asia,2721,32037499
Italy,ita,Europe,1722,26340986
Japan,jpn,East Asia,2872,36916012
Russian Federation,rus,East Europe,1847,27387456
South Africa,zaf,Africa,879,9794857
South Korea,kor,East Asia,1643,21934785
United States of America,usa,North America,6527,87044191
#!/usr/bin/python
import json
f = open('Downloads/test_la_zip_code_areas_2012.json', 'r')
json_contents = json.loads(f.read())
features = json_contents["features"]
for i in features:
i["id"] = i["properties"]["external_id"]
# If shrinking the size of the file is important,
# the properties node could be deleted afterwards:
# del i["properties"]
out_file = open("out_la_zip_code_areas_2012.json", "w")
out_file.write(json.dumps(features))
# out_file will not be sorted, which shouldn't affect anything,
# but to have it be sorted, use sort_keys=True in json.dumps
out_file.close()
#!/usr/bin/python
import json
f = open('Downloads/test_la_zip_code_areas_2012.json', 'r')
json_contents = json.loads(f.read())
features = json_contents["features"]
for i in features:
i["id"] = i["properties"]["external_id"]
# If shrinking the size of the file is important,
# the properties node could be deleted afterwards:
# del i["properties"]
out_file = open("out_la_zip_code_areas_2012.json", "w")
out_file.write(json.dumps(features))
# out_file will not be sorted, which shouldn't affect anything,
# but to have it be sorted, use sort_keys=True in json.dumps
out_file.close()
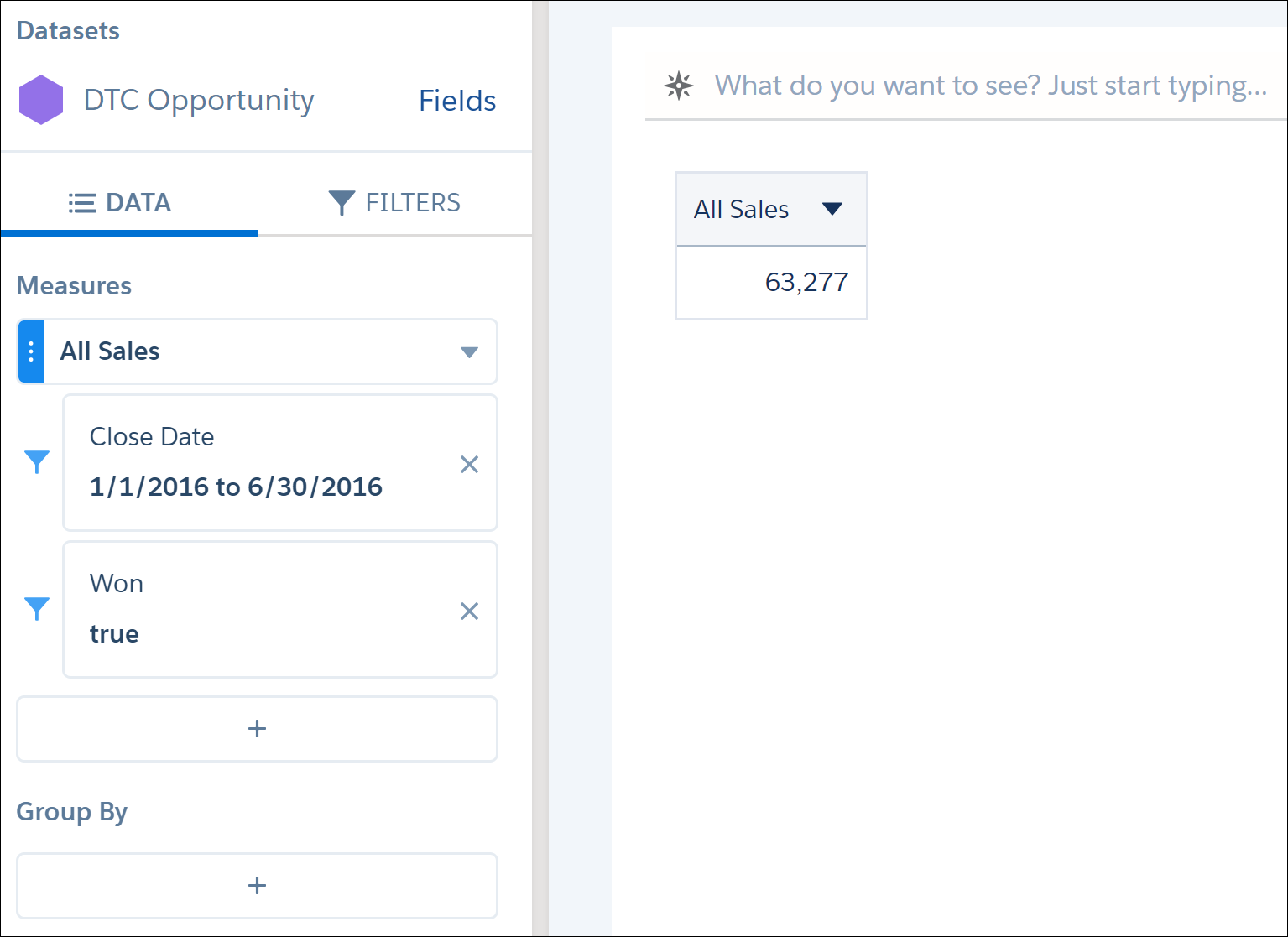
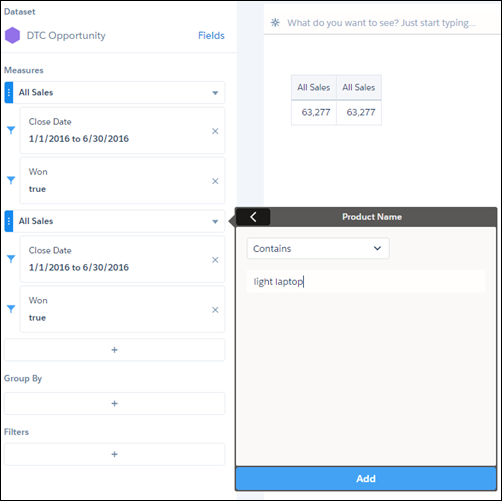
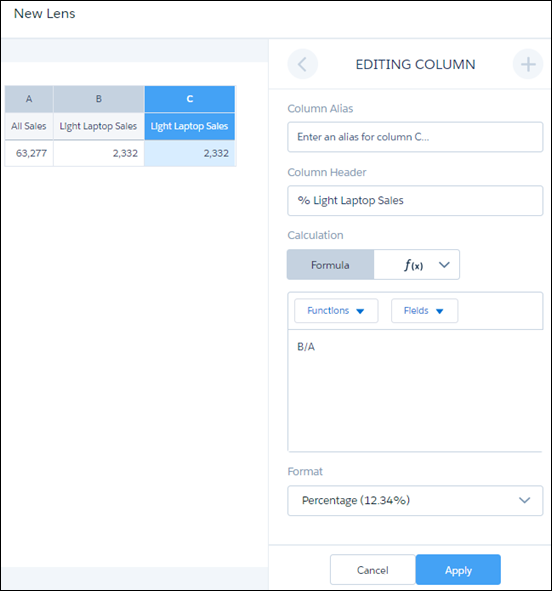
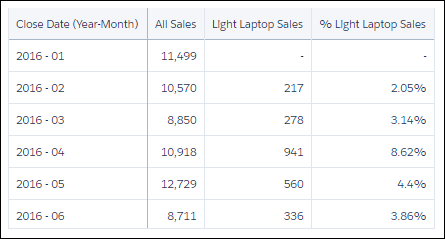
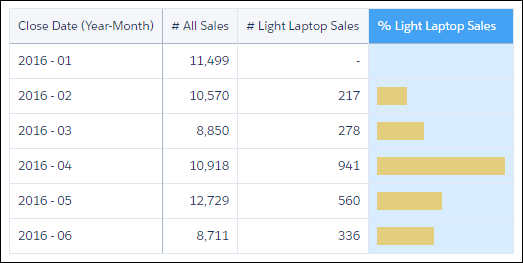
如图所示,当您将鼠标悬停在其图标上时,比较表是基于列的可视化。它与您之前看到的可视化不同。每列都有自己的过滤器和度量,一些列可用于进行计算。您还可以添加最多四个应用于每列的分组,稍后您将看到。让我们用以下列创建一个比较表。 A栏包含所有赢得的机会。 B栏包含所有轻松笔记本电脑的机会。过滤器是Product Family = Light Laptop。 C栏包含计算值,其中总销售额占笔记本电脑销售额的百分比。计算是(# of light laptop sales / # of all sales) x 100